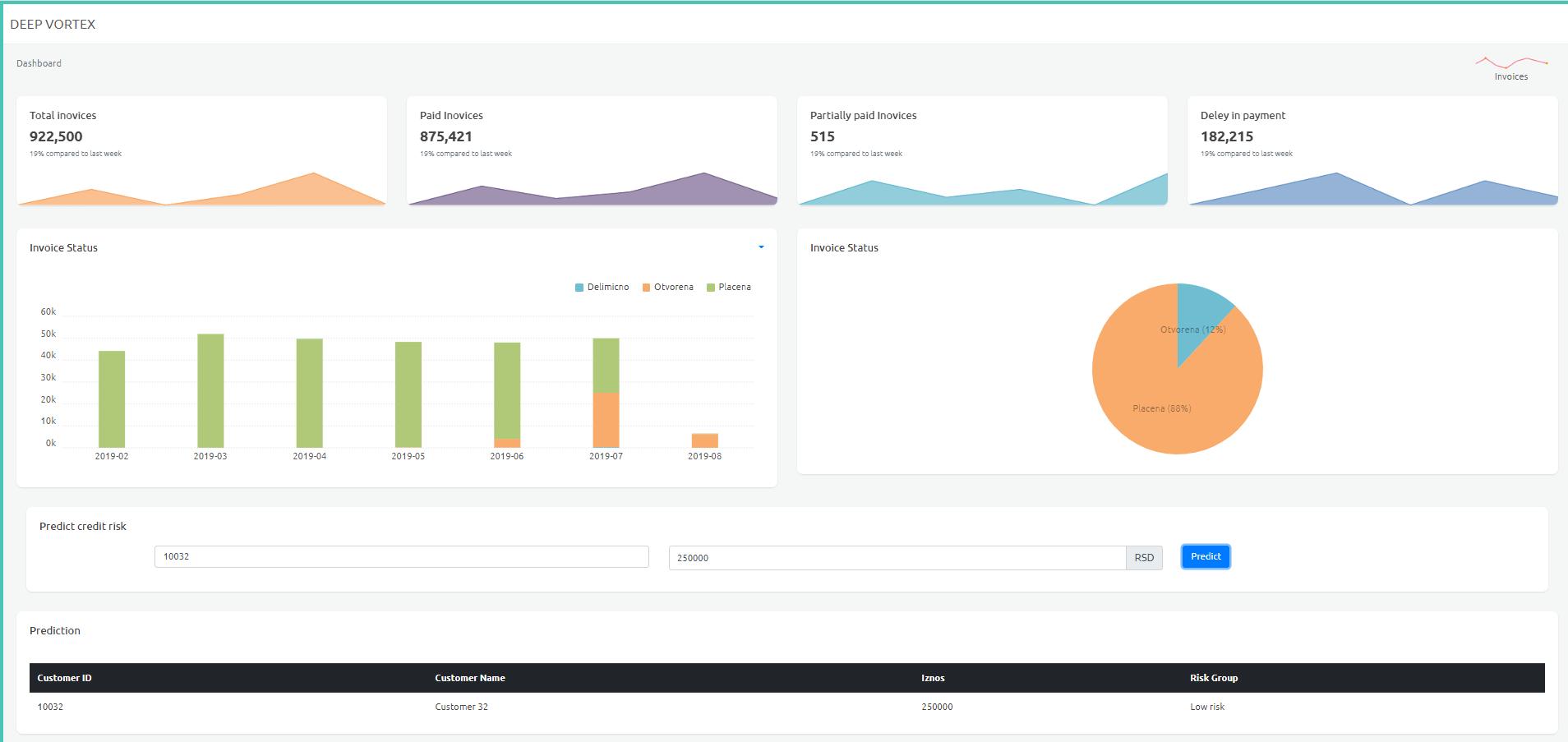
Credit Risk Assessment
Project Brief
In September 2019, IBM together with Institute of Contemporary Sciences and Nelt Group, organized an IBM datathon – data science competition for companies, start-ups, professionals, academics and students. Datahon was organized at ICT Hub in Belgrade, where Deep Vortex team had 24 hours to come up with the winning solution, later presented on IBM’s Think Summit in October 2019 and in Mathematical Institut of the Serbian Academy of Sciences and Arts (SANU) in December 2019.
Introduction
The goal of the competition was to develop a client credit risk scoring model for large distribution and logistics company – Nelt, by designing and implementing risk assessment and machine learning methodologies and concepts in IBM Watson studio. Teams had at their disposal datasets provided by Nelt consisting of client’s transactions data and Qube’s platform was used to obtain clients financial and ownership data. Deep Vortex team has developed solution which helps in establishing an equilibrium between different needs of internal and external stakeholders: finance department with the goal to maintain company’s financial stability, sales department to sell more goods and co-operant resellers to receive optimal amount of goods.
Challange
As one of the largest distribution and logistics company in the region, Nelt has a portfolio of a very diverse customer base, which differ in size, needs, procedures, geographies and industries. Moreover, significant portion of those clients aren’t obliged to report specific performance information to the public, which makes it troublesome to assess financial stability and potential risk levels. In order to minimize number of instances where their clients end up with more products than they could manage due liquidity or other operational issues, Deep Vortex team has developed the most precise and robust solution for predicting risk level for each client, regardless of industry, size, region, while also providing a risk assessment for proposed amount of goods to be distributed. In this way, proposed solution could help in automation of decision-making process by optimizing credit line levels which to be offered to each business partner.
Methodology
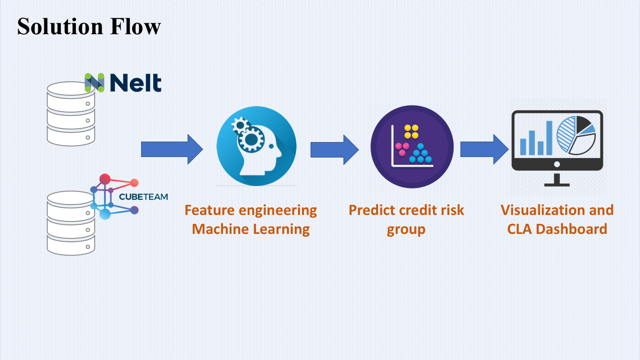
Data Engineering
Data acquisition, preparation, labelling and analytics was one of the most time consuming tasks. Deep Vortex team combined wide range of supporting technologies, methodologies and resources to perform on this very important task. First, we used OCR to correctly mark all position in financial reports, which were previously encrypted, in order to better understand business meaning of each potential variable.
Machine Learning
In the next step, we aligned both datasets and processed it by engineering various ratios and metrics describing companies credit score on part of the data where we had inputs labels. After applying <strong>feature selection</strong> and testing different potential combinations of indicators on predictive model’s accuracy, we have identified several most important variables from which we developed features representing different liquidity, cash flow, indebtedness, profitability and operations efficiency indicators. Next, we applied inference from that model to unlabelled part od dataset and performed different data mining, unsupervised learning approaches to derive 75 risk clusters to company is exposed to. Lastly, we implement different weighting, aggregating and smoothing techniques to obtain main risk segments.